AI tools for NVIDIA TensorRT-LLM
Related Tools:
DeepSeek-v3
DeepSeek-v3 is a leading AI model and cutting-edge AI solution that provides users with state-of-the-art language models for free, without limitations or system busyness. It offers stable and efficient output, supports multiple languages and deployment options, and allows users to access cutting-edge AI solutions through a simple three-step process. DeepSeek-v3 is a major breakthrough in speed, performance, and cost-effectiveness compared to previous models, making it a competitive choice for various AI tasks.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing solutions for cloud services, data center, embedded systems, gaming, and creating graphics cards and GPUs. They offer a wide range of products and services, including AI-driven platforms for life sciences research, end-to-end AI platforms, generative AI deployment, advanced simulation integration, and more. NVIDIA focuses on modernizing data centers with AI and accelerated computing, offering enterprise AI platforms, supercomputers, advanced networking solutions, and professional workstations. They also provide software tools for AI development, data center management, GPU monitoring, and more.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing, providing hardware and software solutions for gaming, entertainment, data centers, edge computing, and more. Their platforms like Jetson and Isaac enable the development and deployment of AI-powered autonomous machines. NVIDIA's AI applications span various industries, from healthcare to manufacturing, and their technology is transforming the world's largest industries and impacting society profoundly.
Nebius AI
Nebius AI is an AI-centric cloud platform designed to handle intensive workloads efficiently. It offers a range of advanced features to support various AI applications and projects. The platform ensures high performance and security for users, enabling them to leverage AI technology effectively in their work. With Nebius AI, users can access cutting-edge AI tools and resources to enhance their projects and streamline their workflows.
NVIDIA Run:ai
NVIDIA Run:ai is an enterprise platform for AI workloads and GPU orchestration. It accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. The platform significantly enhances GPU efficiency and workload capacity by pooling resources across environments and utilizing advanced orchestration. NVIDIA Run:ai provides unparalleled flexibility and adaptability, supporting public clouds, private clouds, hybrid environments, or on-premises data centers.
SpiderX AI
SpiderX AI is an advanced AI platform offering a range of AI agents for various industries such as recruitment, customer service, automotive sales, research, restaurant booking, and event management. The platform provides specialized AI solutions to streamline processes, enhance customer experiences, and optimize operations. With a focus on efficiency and precision, SpiderX AI's agents are designed to solve complex problems and deliver insights with unrivaled expertise.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Lambda
Lambda is a superintelligence cloud platform that offers on-demand GPU clusters for multi-node training and fine-tuning, private large-scale GPU clusters, seamless management and scaling of AI workloads, inference endpoints and API, and a privacy-first chat app with open source models. It also provides NVIDIA's latest generation infrastructure for enterprise AI. With Lambda, AI teams can access gigawatt-scale AI factories for training and inference, deploy GPU instances, and leverage the latest NVIDIA GPUs for high-performance computing.
Paperspace
Paperspace is an AI tool designed to develop, train, and deploy AI models of any size and complexity. It offers a cloud GPU platform for accelerated computing, with features such as GPU cloud workflows, machine learning solutions, GPU infrastructure, virtual desktops, gaming, rendering, 3D graphics, and simulation. Paperspace provides a seamless abstraction layer for individuals and organizations to focus on building AI applications, offering low-cost GPUs with per-second billing, infrastructure abstraction, job scheduling, resource provisioning, and collaboration tools.
Haechi AI
Haechi AI is an all-in-one AI platform that provides access to advanced AI models for various purposes such as education, content creation, retail, development, and innovation. It offers a range of features including creating questions, completing homework, correcting grammar, writing theses, developing projects, generating images, summarizing texts, translating languages, enhancing presentations, and more. The platform is designed to empower users with powerful tools and fine-tuned models to boost efficiency and productivity in their tasks. With Haechi AI, users can leverage cutting-edge AI technology without the need for downloading or installing anything, enabling them to push the boundaries of technology effortlessly.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.

NVentures
NVentures is NVIDIA's venture capital arm that invests in technology visionaries solving complex problems to reshape the world. They build long-term partnerships with bold teams to accelerate their journeys. NVentures provides insightful diligence and resources to unlock the potential of innovative companies.
Cirrascale Cloud Services
Cirrascale Cloud Services is an AI tool that offers cloud solutions for Artificial Intelligence applications. The platform provides a range of cloud services and products tailored for AI innovation, including NVIDIA GPU Cloud, AMD Instinct Series Cloud, Qualcomm Cloud, Graphcore, Cerebras, and SambaNova. Cirrascale's AI Innovation Cloud enables users to test and deploy on leading AI accelerators in one cloud, democratizing AI by delivering high-performance AI compute and scalable deep learning solutions. The platform also offers professional and managed services, tailored multi-GPU server options, and high-throughput storage and networking solutions to accelerate development, training, and inference workloads.
Streetbeat
Streetbeat is an innovative investment platform that simplifies and automates investing activities. It serves as a solution for navigating the complexity of financial markets and deriving actionable insights. Streetbeat offers AI Agents for businesses to automate tasks and enhance client services, while individuals can access an AI-powered financial advisor to manage investments. The platform aims to make investing more accessible and efficient for users.
OyeeahAI
OyeeahAI is an all-in-one AI tools platform that offers a wide range of AI-powered features for content generation, document writing, social media automation, and more. Users can access advanced AI technologies to streamline tasks, create high-quality content, and manage support tickets efficiently. The platform provides a user-friendly dashboard, multilingual support, custom templates, and tools like AI content detector, chatbot customization, plagiarism detection, brand voice creation, and social media scheduling. OyeeahAI aims to revolutionize content creation and business processes by leveraging the power of AI technology.
NVIDIA Toronto AI Lab
The NVIDIA Toronto AI Lab is a research laboratory focused on advancing the state-of-the-art in artificial intelligence. The lab's researchers are working on a wide range of AI topics, including deep learning, machine learning, computer vision, natural language processing, and robotics.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.

MagiScan
MagiScan is a 3D scanner app available for iOS and Android platforms. It utilizes AI technology to provide users with a simple and professional tool for creating high-quality 3D models. The app offers various export formats, affordable pricing, and seamless integration with NVIDIA Omniverse. MagiScan aims to digitize objects quickly to meet the increasing demand for 3D content. With a focus on user feedback, the app caters to both professionals and ordinary users, striving to erase the boundary between the real and virtual worlds.

Google Gemma
Google Gemma is a lightweight, state-of-the-art open language model (LLM) developed by Google. It is part of the same research used in the creation of Google's Gemini models. Gemma models come in two sizes, the 2B and 7B parameter versions, where each has a base (pre-trained) and instruction-tuned modifications. Gemma models are designed to be cross-device compatible and optimized for Google Cloud and NVIDIA GPUs. They are also accessible through Kaggle, Hugging Face, Google Cloud with Vertex AI or GKE. Gemma models can be used for a variety of applications, including text generation, summarization, RAG, and both commercial and research use.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).

Qwen-TensorRT-LLM
Qwen-TensorRT-LLM is a project developed for the NVIDIA TensorRT Hackathon 2023, focusing on accelerating inference for the Qwen-7B-Chat model using TRT-LLM. The project offers various functionalities such as FP16/BF16 support, INT8 and INT4 quantization options, Tensor Parallel for multi-GPU parallelism, web demo setup with gradio, Triton API deployment for maximum throughput/concurrency, fastapi integration for openai requests, CLI interaction, and langchain support. It supports models like qwen2, qwen, and qwen-vl for both base and chat models. The project also provides tutorials on Bilibili and blogs for adapting Qwen models in NVIDIA TensorRT-LLM, along with hardware requirements and quick start guides for different model types and quantization methods.

TensorRT-Model-Optimizer
The NVIDIA TensorRT Model Optimizer is a library designed to quantize and compress deep learning models for optimized inference on GPUs. It offers state-of-the-art model optimization techniques including quantization and sparsity to reduce inference costs for generative AI models. Users can easily stack different optimization techniques to produce quantized checkpoints from torch or ONNX models. The quantized checkpoints are ready for deployment in inference frameworks like TensorRT-LLM or TensorRT, with planned integrations for NVIDIA NeMo and Megatron-LM. The tool also supports 8-bit quantization with Stable Diffusion for enterprise users on NVIDIA NIM. Model Optimizer is available for free on NVIDIA PyPI, and this repository serves as a platform for sharing examples, GPU-optimized recipes, and collecting community feedback.
ChatRTX
ChatRTX is a demo app that enables personalization of a GPT large language model connected to user content using retrieval-augmented generation (RAG), TensorRT-LLM, NVIDIA NIM microservices, and RTX acceleration. Users can query a custom chatbot for contextually relevant answers, including voice input support. The app runs locally on Windows RTX PCs, supporting various file formats for quick loading into the library.
End-to-End-LLM
The End-to-End LLM Bootcamp is a comprehensive training program that covers the entire process of developing and deploying large language models. Participants learn to preprocess datasets, train models, optimize performance using NVIDIA technologies, understand guardrail prompts, and deploy AI pipelines using Triton Inference Server. The bootcamp includes labs, challenges, and practical applications, with a total duration of approximately 7.5 hours. It is designed for individuals interested in working with advanced language models and AI technologies.
awesome-cuda-tensorrt-fpga
Okay, here is a JSON object with the requested information about the awesome-cuda-tensorrt-fpga repository:
rank_llm
RankLLM is a suite of prompt-decoders compatible with open source LLMs like Vicuna and Zephyr. It allows users to create custom ranking models for various NLP tasks, such as document reranking, question answering, and summarization. The tool offers a variety of features, including the ability to fine-tune models on custom datasets, use different retrieval methods, and control the context size and variable passages. RankLLM is easy to use and can be integrated into existing NLP pipelines.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.
Awesome-LLM-Inference
Awesome-LLM-Inference: A curated list of 📙Awesome LLM Inference Papers with Codes, check 📖Contents for more details. This repo is still updated frequently ~ 👨💻 Welcome to star ⭐️ or submit a PR to this repo!

Awesome_LLM_System-PaperList
Since the emergence of chatGPT in 2022, the acceleration of Large Language Model has become increasingly important. Here is a list of papers on LLMs inference and serving.
rtp-llm
**rtp-llm** is a Large Language Model (LLM) inference acceleration engine developed by Alibaba's Foundation Model Inference Team. It is widely used within Alibaba Group, supporting LLM service across multiple business units including Taobao, Tmall, Idlefish, Cainiao, Amap, Ele.me, AE, and Lazada. The rtp-llm project is a sub-project of the havenask.

Awesome-LLM
Awesome-LLM is a curated list of resources related to large language models, focusing on papers, projects, frameworks, tools, tutorials, courses, opinions, and other useful resources in the field. It covers trending LLM projects, milestone papers, other papers, open LLM projects, LLM training frameworks, LLM evaluation frameworks, tools for deploying LLM, prompting libraries & tools, tutorials, courses, books, and opinions. The repository provides a comprehensive overview of the latest advancements and resources in the field of large language models.
awesome-production-llm
This repository is a curated list of open-source libraries for production large language models. It includes tools for data preprocessing, training/finetuning, evaluation/benchmarking, serving/inference, application/RAG, testing/monitoring, and guardrails/security. The repository also provides a new category called LLM Cookbook/Examples for showcasing examples and guides on using various LLM APIs.
llm-inference-solutions
A collection of available inference solutions for Large Language Models (LLMs) including high-throughput engines, optimization libraries, deployment toolkits, and deep learning frameworks for production environments.
Awesome-LLM-Compression
Awesome LLM compression research papers and tools to accelerate LLM training and inference.
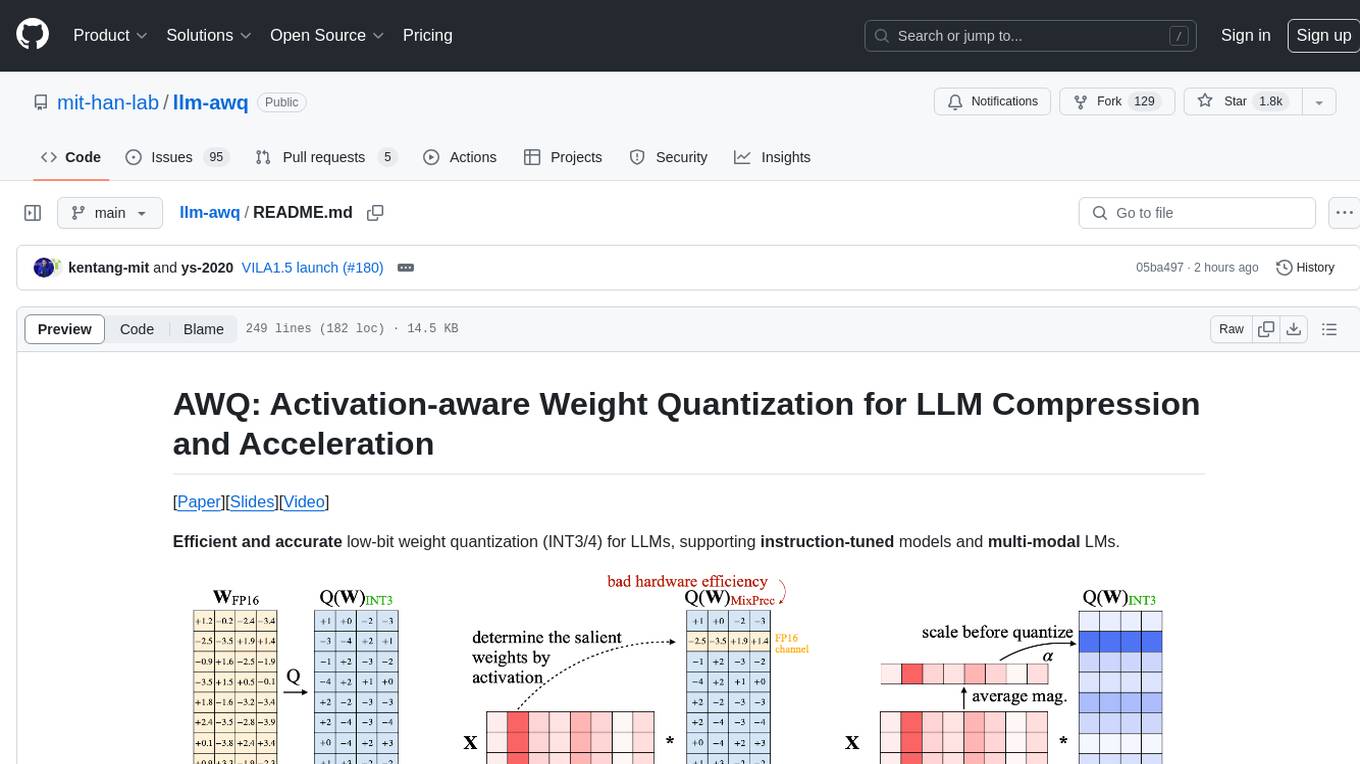
llm-awq
AWQ (Activation-aware Weight Quantization) is a tool designed for efficient and accurate low-bit weight quantization (INT3/4) for Large Language Models (LLMs). It supports instruction-tuned models and multi-modal LMs, providing features such as AWQ search for accurate quantization, pre-computed AWQ model zoo for various LLMs, memory-efficient 4-bit linear in PyTorch, and efficient CUDA kernel implementation for fast inference. The tool enables users to run large models on resource-constrained edge platforms, delivering more efficient responses with LLM/VLM chatbots through 4-bit inference.
awesome-local-llms
The 'awesome-local-llms' repository is a curated list of open-source tools for local Large Language Model (LLM) inference, covering both proprietary and open weights LLMs. The repository categorizes these tools into LLM inference backend engines, LLM front end UIs, and all-in-one desktop applications. It collects GitHub repository metrics as proxies for popularity and active maintenance. Contributions are encouraged, and users can suggest additional open-source repositories through the Issues section or by running a provided script to update the README and make a pull request. The repository aims to provide a comprehensive resource for exploring and utilizing local LLM tools.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.